Ha lottóztál már, akkor valószínűleg felmerült benned, hogy a kihúzott számok valóban véletlenszerűek-e. A számokat hosszú évekre visszamenőleg közzéteszik, így ezt bárki ellenőrizheti, ha megfelelő statisztikai ismeretek birtokában van. A lottószámok véletlenszerűségének vizsgálatához, a középiskolai statisztikai anyagot meghaladó ismeretekre van szükség, ezért egyszerűsítünk rajta, és egyes részeredményeket nem igazolunk. Az egyszerűbb példa, amelyet megvizsgálunk, egy pénzfeldobásos eseménysorozat. 200-szor feldobunk egy pénzérmét, és azt vizsgáljuk, hogy ez szabályos-e, illetve fogalmazhatnánk úgy is, hogy a feldobások során nem csalt-e valaki.
Nézzünk egy eredményt, ahol az egyesek jelölik az írást, a nullák pedig a fejet.

A fenti új fogalmakat próbáljuk megtölteni tartalommal, amely kapcsolódik a példánkhoz. Tekintsük a 200 pénzfeldobás eredményét, melyek binomiális eloszlást követnek. A pénzfeldobásokat többször elvégezzük egymás után, és felírjuk, hogy hány esetben volt fej és írás. Ha elégendően sokszor megismételjük, akkor a kapott eredményeket hisztogrammal ábrázolhatjuk, az \(x\) tengelyen legyenek 0-200-ig az értékek, hogy hány esetben volt a 200 pénzfeldobás közül pl. fej, az oszlopok magassága pedig azt mutatja meg, hogy a sokszor elvégzett kísérletek hány százalékában volt az adott, jelen esetben “fej” eredmény. A grafikon egy szimmetrikus alakzatot mutat, amely az elméleti eloszlást jeleníti meg. Ebben lehetnek kisebb-nagyobb torzulások, ha valós pénzfeldobást vizsgálunk.
A grafikon egy szimmetrikus alakzatot mutat, amely az elméleti eloszlást jeleníti meg. Ebben lehetnek kisebb-nagyobb torzulások, ha valós pénzfeldobást vizsgálunk.
Az utolsó megállapításból egy fontos következtetést vonhatunk le, ha egy kissé átfogalmazzuk. Ha több mintát vizsgálunk, akkor az 50-50%-os eredményt csak az esetek 5%-ban várjunk el, azaz meglehetősen ritka esemény. Ez azonnal egy figyelmeztető jel lehet egy adatsor elemzésénél, főleg akkor, ha ezt a mérést rendszeresen elvégezzük és az esetek többségében pont az 50-50%-os eredményt kapjuk.
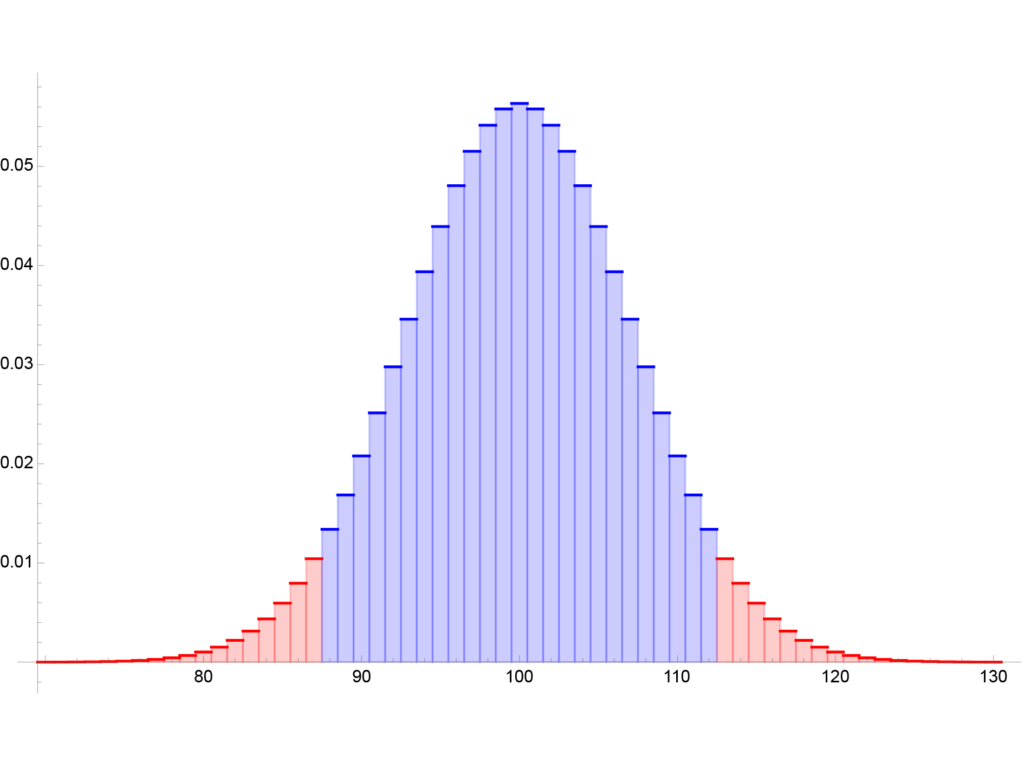 Ha a kékkel jelölt oszlopok magasságát összeadjuk, akkor az egyes kimenetekhez tartozó valószínűségeket összegeztük, amelyre az elvár (minimum) érték 90%, a feltételezésünk szerint – ez a konfidencia szint. Ebből már könnyen meghatározható a konfidencia tartomány, azaz milyen arányokat kapunk nagy (minimum 90%-os) valószínűséggel. Ha azoknak az eseteknek a valószínűségét összegezzük, amikor 88-112 között van a fej dobások száma a 200-ból, akkor elérjük a kívánt szintet, azaz a konfidencia intervallum \([88,\,112]\). Fordítsuk meg a gondolatmenetet, annak a valószínűsége, hogy a 200 pénzfeldobás esetén \(0,\,1,\,2,\,\ldots,\,87\) valamelyike a fejdobások száma, azaz 200 dobásból, 0 vagy 1 vagy 2 vagy… a fej érték), nem több mint 5% – összesen. Ugyanez mondható el a jobb oldali 113-200-as tartományra is. Így a konfidencia intervallumon kívüli események összes valószínűsége 10%.
Ha a kékkel jelölt oszlopok magasságát összeadjuk, akkor az egyes kimenetekhez tartozó valószínűségeket összegeztük, amelyre az elvár (minimum) érték 90%, a feltételezésünk szerint – ez a konfidencia szint. Ebből már könnyen meghatározható a konfidencia tartomány, azaz milyen arányokat kapunk nagy (minimum 90%-os) valószínűséggel. Ha azoknak az eseteknek a valószínűségét összegezzük, amikor 88-112 között van a fej dobások száma a 200-ból, akkor elérjük a kívánt szintet, azaz a konfidencia intervallum \([88,\,112]\). Fordítsuk meg a gondolatmenetet, annak a valószínűsége, hogy a 200 pénzfeldobás esetén \(0,\,1,\,2,\,\ldots,\,87\) valamelyike a fejdobások száma, azaz 200 dobásból, 0 vagy 1 vagy 2 vagy… a fej érték), nem több mint 5% – összesen. Ugyanez mondható el a jobb oldali 113-200-as tartományra is. Így a konfidencia intervallumon kívüli események összes valószínűsége 10%.