### F-eloszlás és az F-érték meghatározása
Az **F-eloszlás** (Fisher-féle eloszlás) egy aszimmetrikus valószínűségi eloszlás, amelyet két variancia hányadosának vizsgálatára használnak. Az F-eloszlást főként **varianciaanalízisben (ANOVA)**, valamint regressziómodellek és különböző statisztikai hipotézisvizsgálatok során alkalmazzák. Az eloszlás alakját két szabadságfok határozza meg: az **osztó** (\(df_1\)) és a **nevező** (\(df_2\)) szabadságfok.
—
### Hogyan működik az F-érték?
– Az **F-érték** a minta varianciák közötti arányt méri:
\[
F = \frac{\text{Csoportok közötti variancia}}{\text{Csoportokon belüli variancia}}
\]
– Az eloszlás aszimmetrikus és csak pozitív értékeket vehet fel.
– Az eloszlás alakja a két szabadságfoktól függ (\(df_1\) és \(df_2\)):
– \(df_1\) az osztó szabadságfoka (pl. a csoportok száma),
– \(df_2\) a nevező szabadságfoka (pl. a megfigyelések száma mínusz a csoportok száma).
—
### F-érték meghatározása táblázat alapján
1. **Adott szignifikanciaszinthez (\(\alpha\)):**
– Az F-eloszlás táblázata megadja a kritikus F-értéket az adott **szignifikanciaszint** (\(\alpha\)) és **szabadságfokok** (\(df_1\) és \(df_2\)) alapján.
– Az oszlopok az osztó szabadságfokot (\(df_1\)) jelzik.
– A sorok a nevező szabadságfokot (\(df_2\)) tartalmazzák.
– A megfelelő cellában található a kritikus F-érték az adott \(\alpha\)-hoz.
2. **Példa F-érték meghatározására:**
Tegyük fel, hogy a csoportok száma alapján \(df_1 = 3\), a megfigyelések száma alapján \(df_2 = 20\), és a szignifikanciaszint \(\alpha = 0.05\). A táblázatból kikeresve:
– Az oszlopban \(df_1 = 3\),
– A sorban \(df_2 = 20\),
– A metszéspontban található az F-kritikus érték, például \(F = 3.10\).
Ez azt jelenti, hogy ha a számított F-érték nagyobb, mint \(3.10\), akkor a nullhipotézist elutasítjuk ezen a szignifikanciaszinten.
3. **F-érték jelentése:**
Az F-érték nagyobb értékei azt jelzik, hogy a csoportok közötti variancia szignifikánsan nagyobb, mint a csoportokon belüli variancia, ami a nullhipotézis elvetéséhez vezethet.
—
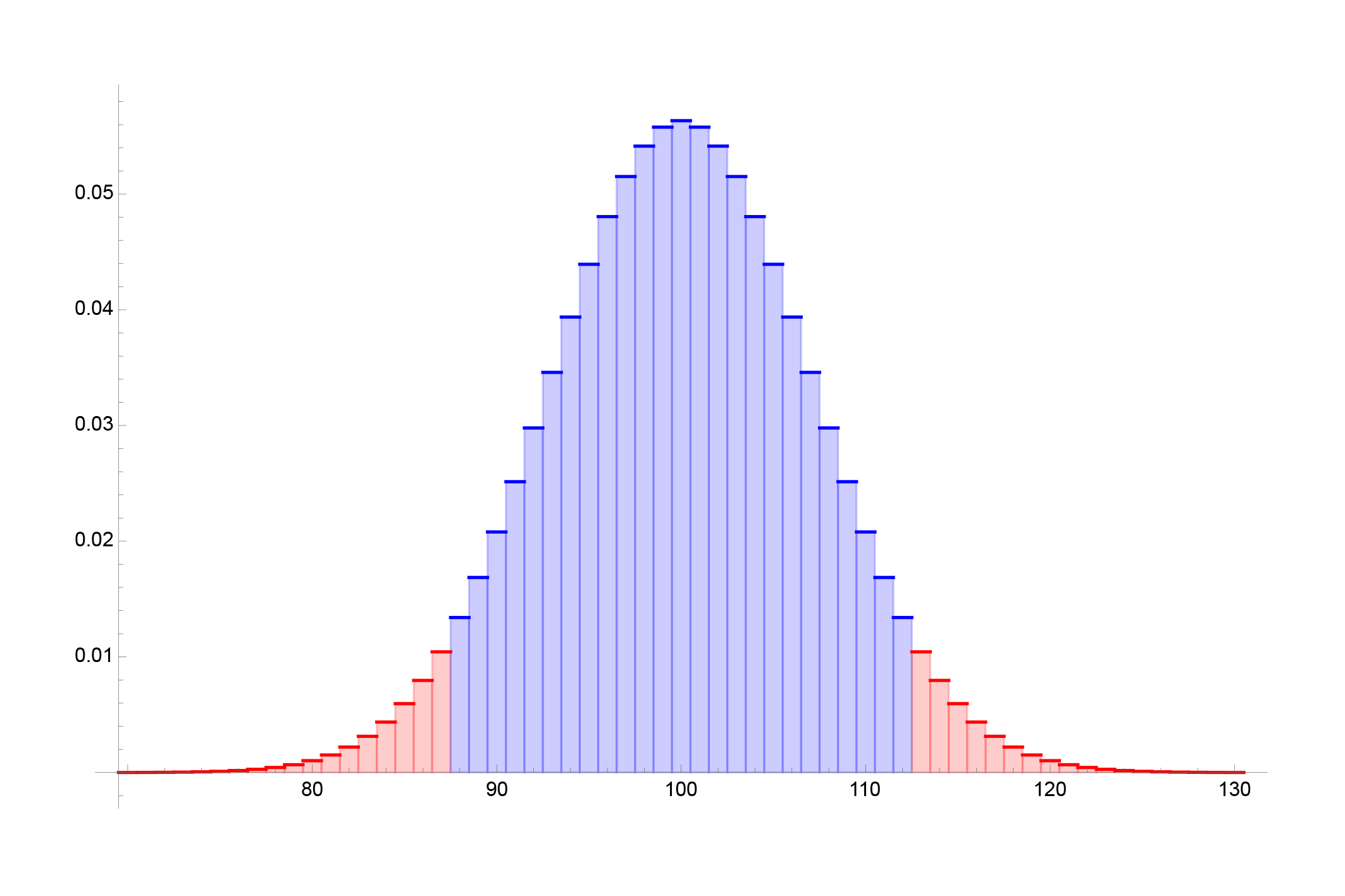
### Hogyan olvasható ki F-érték a PDF-ből (Probability Density Function)?
Az F-eloszlás sűrűségfüggvénye (\(f(F)\)) az F-értékek relatív gyakoriságát jelzi az adott szabadságfokok mellett, de az elemzésekhez általában a kumulált valószínűség (CDF) szükséges. A PDF alapján csak az F-eloszlás görbéje és az egyes értékek relatív valószínűségei láthatók. Az eloszlás táblázata vagy szoftverek (pl. Excel, R, SPSS) segítenek meghatározni az adott F-értékhez tartozó valószínűséget vagy kritikus értéket.
—
### Részletes útmutató:
1. **Adott szignifikanciaszinthez (\(\alpha\)):**
Ha \(\alpha\), \(df_1\) és \(df_2\) ismert, akkor a táblázatból meghatározható a kritikus F-érték. Ez az a küszöbérték, amelyet az F-próba eredményeinek értelmezésekor használunk.
2. **Adott F-értékhez tartozó valószínűség (\(P\)):**
Ha egy konkrét F-értékhez tartozó valószínűséget keresünk, akkor a szabadságfokok és szoftverek segítségével meghatározható, hogy ez az érték milyen szignifikanciaszint mellett szignifikáns.
3. **Értelmezés:**
– Ha az F-érték meghaladja a kritikus értéket, akkor a csoportok közötti különbségek szignifikánsak.
– Ha az F-érték kisebb, mint a kritikus érték, akkor nincs elegendő bizonyíték a csoportok közötti szignifikáns különbség megállapítására.
—
Az F-eloszlás tehát kulcsfontosságú az olyan statisztikai elemzésekben, ahol varianciák hányadosát kell értékelni, különösen ANOVA és regressziós modellek esetében. Az eloszlás lehetővé teszi, hogy következtetéseket vonjunk le a csoportok közötti eltérések szignifikanciájáról.